机器学习应用用FPGA技术实现要注意的几点因素
神经网络、算法和传感器等都还是处于不断演化的过程,一款固定的、标准的设计平台面对这些风云变幻的演进根本无力招架。此时此刻,FPGA技术成为数百家嵌入式视觉企业开发的首选,其中用于机器学习领域的已经超过40家。
越来越多的辅助驾驶、无人机、虚拟现实/增强现实、医学诊断、工业视觉等应用,为了追逐更高性能/差异化,纷纷对机器学习产生浓厚的兴趣。
已有几家初创企业在开发专门的机器学习芯片,但上述这些应用不仅仅要集成机器学习,还有计算机视觉,传感器融合和连接。如果要开发这么一整套独特的性能组合,可能要花费几亿美元才能推出第一款芯片,而且从各种规格的确定落实到推出样片,可能需要三年以上。
更别提这三年过程当中还有一个挑战:那就是神经网络、算法和传感器等都还是处于不断演化的过程,一款固定的、标准的设计平台面对这些风云变幻的演进根本无力招架。此时此刻,FPGA技术成为数百家嵌入式视觉企业开发的首选,其中用于机器学习领域的已经超过40家。
那么问题来了,面对市场上最热门的人工智能CPU/GPU芯片,全可编程方案的优缺点是什么?产量达到多少以后就不再合适?
秒杀对手的性能,是怎么算出来的?
赛灵思有一个公开的性能对比:针对 Zynq SoC 的 reVISION堆栈与 Nvidia Tegra X1 进行基准对比,得出下图这个惊人的数据: reVISION 堆栈在机器学习方面单位功耗图像捕获速度提升 6 倍,在计算机视觉处理的帧速率提升 42 倍,时延仅为 1/5(以毫秒为单位),这些对实时应用而言都是至关重要的。

既然和竞争对手做对比,一定是在相同价格的芯片之上做的一些性能对比。在接到EDN记者的疑问后,赛灵思嵌入式视觉和SDSoC高级产品经理Nick Ni用详细数据解答了此疑问。
6倍、42倍和1/5,这几个数据都是基于同一基础的。
“像机器学习的6倍的图像/秒/瓦是用谷歌来做编程。比如Xilinx我们使用ZU9可以达到370,我们的功率达到7W,我们使用一样的GoogleNet,我们可以看到Nvidia已经在公开他们最好的数据,所以我们就用他们这些数字,所以就算出来6X。”Ni指出。
在42倍帧/秒/瓦,则是用最优化的这些库来做比较。
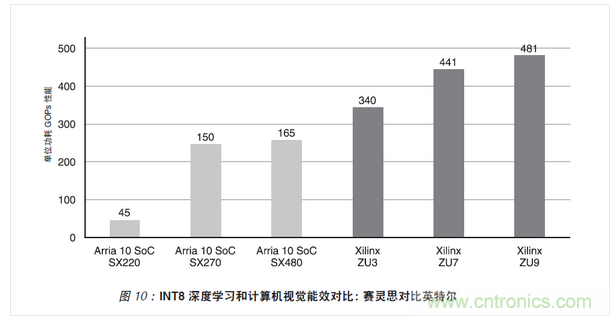
在竞争分析中使用英特尔(Altera)的 Arria 10 器件与赛灵思的 Zynq UltraScale+ MPSoC 对比。在进行嵌入式视觉应用计算效率比较时,选择的器件有可比的 DSP 密度和器件功耗:
·Arria 10 SoC:SX220、SX270 和 SX480
·Zynq UltraScale+ MPSoC:ZU3、ZU7 和 ZU9 器件
重点比较能用于包括深度学习和计算机视觉在内的众多应用的通用 MACC 性能。英特尔的 MACC 性能基于运用预加法器的算子。但是这种实现方案产生的是乘积项的和,而非单独的乘积项。因此英特尔的预加法器不适用高效深度学习或计算机视觉运算。
在本计算效率分析中,每个器件的功耗使用赛灵思的2016.4 版 Power Estimator 工具和英特尔的 16.0.1 版 EPE Power Estimate 工具进行估算,并根据下列假设得出:
1.90% DSP 占用率
2.英特尔器件 - 速度等级为:2L, 最大频率下供电电压为 0.9V
3.赛灵思器件 -速度等级为 1L, 最大频率下供电电压为 0.72V
4.时钟速率为 DSP Fmax 时逻辑利用率为 70%
5.时钟速率为 DSP 最大频率的一半时,Block RAM 利用率为 90%
6.DSP 翻转率为 12.5%
7.功耗特征:“典型功耗”
下图所示的即为深度学习和计算机视觉运算的能效对比。与英特尔的 Arria 10 SoC 器件相比,赛灵思器件能让深度学习和计算机视觉运算的计算效率提高 3-7 倍。
响应速度来源于架构
响应速度在汽车驾驶中直接影响着安全距离。
“1/5时延有不一样的方法来算,我们的算法是直接用了深度学习/机器学习,因为很多时候如果知道深度学习的话,可以用不一样的方法来做,你输入一个图像进去,反应速度就是这个图像什么时候能够出来,我们可以看到5倍的速率差异。”Ni表示。现在一些硬件的专业客户如果他们花费很多的精力或者是时间的投入,他们有可能可以实现只有1/12的时延。
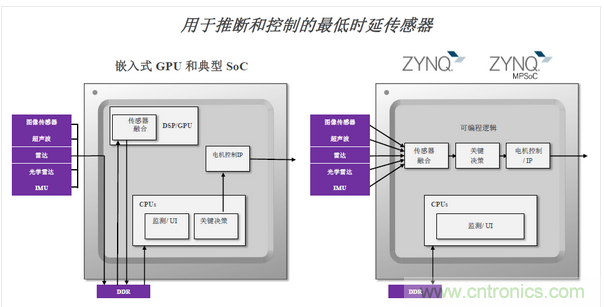
响应速度快,其实和赛灵思的架构是息息相关的,如下图所示。“典型的嵌入式的GPU和典型的SoC,他的传感器的数据是需要外部存储,在处理过程中需要不断的去访问外部存储。但是Zynq能直接获得数据流,直接经过传感器融合处理,再进行决策,响应时间大大缩短。”
如何满足机器学习的这三点诉求?
我们从客户那里看到三方面的需求,赛灵思公司战略与市场营销部高级副总裁Steve Glaser表示,“第一,他们希望机器学习的智能性有所提高,同时他们也希望系统能够实现及时的快速响应来应对一切外部事件,比如行人从车前经过,比如神经网络或者相关技术的市场变化。”

赛灵思公司战略与市场营销部高级副总裁Steve Glaser
其次,成本要低、功耗要低。他们希望能够以非常高的效率使用非常先进的算法。最后,他们需要灵活性——因为一切都在不断的变化:神经网络和算法、传感器的类型配置和组合等。
“我们能够帮助客户来优化他们的数据流,从传感器到视觉处理,再到机器学习推断,一直到控制系统。另外我们也通过先预置的硬件,再加上可以编程的软件,为客户提供前所未有的灵活性。”Glaser表示,这也就意味着,在不实质性改变硬件、包括板和芯片的情况下,客户就能够升级优化到最新的神经网络、算法以及传感器的类型配置。
reVISION堆栈包含一些基础的平台,可以支持算法的开发,而且它带有非常符合行业标准的库和元素,针对于计算机、视觉以及机器学习都是非常重要的,这些框架包括在机器学习领域的Caffe,以及在计算机视觉领域就是OpenVX。
专门的开发人才与生态环境
在GPU体系中,有一大群开发者不断提供优秀的设计,实现良性循环,例如NVidia推出的运算平台CUDA,包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。
全可编程方案好是好,可是会的人少。
“reVISION可以简单地实现一个工程,直接把一个Caffe训练好的神经网络模型部署到Zynq里。Zynq本身已经包括了优化的硬件,可以满足神经网络的计算需求。如果需要定制自己的神经网络,只要把Caffe模型输入到Zynq即可马上跑起来。从开发角度讲,Zynq特别像CUDA,可以直接釆用GPU或CPU训练好的神经网络。”
现在reVISION堆栈有大量符合行业标准的库和框架,开发时间可以大大压缩,专门针对那些并没有硬件方面专业知识的嵌入式软件或者系统级工程师。
传统的模式中,赛灵思提供芯片以及开发环境当中20%的解决方案,剩下的80%要由客户来完成。“有了这个reVISION堆栈以后,赛灵思能够完成解决方案当中80%的工作,剩下的客户只要完成20%。”Glaser表示。
关键的一点不能漏:reVISION是免费的,赛灵思说自己只赚芯片钱。
成本,多大的量需要寻求替代性方案?
最后,人工智能的硬件生态目前还没确定,从公司角度出发,抢占市场先机和获得成本优势同样重要。
几年前推出Zynq的时候,其低端的版本大批量应用差不多是15美元以下,现在甚至有了更低端的单核版本,与高端产品4核及7核的异构多处理器MPSoC并存,“现在我们有从10美元到几十美元的组合。”Glaser指出。
虽然达不到几千万或数亿那么高的量,由于不再是FPGA了,而是混合的SoC,带有可以编程的逻辑和IO,所以在量方面已经建立了一个非常强大的成本优化的产品组合,能够提供非常好的量化的性价比。
“我们关注那些数量级在几百万的应用。一旦有一些应用实现了商业化,达到了几千万甚至是几亿的数量级,就会有别的更低成本的方案进来。”Glaser指出,赛灵思关注的只是几百万的数量级追求差异化的应用,而不是“够用就好”的批量数千万的商业化应用 。
